Input / output design¶
Basics¶
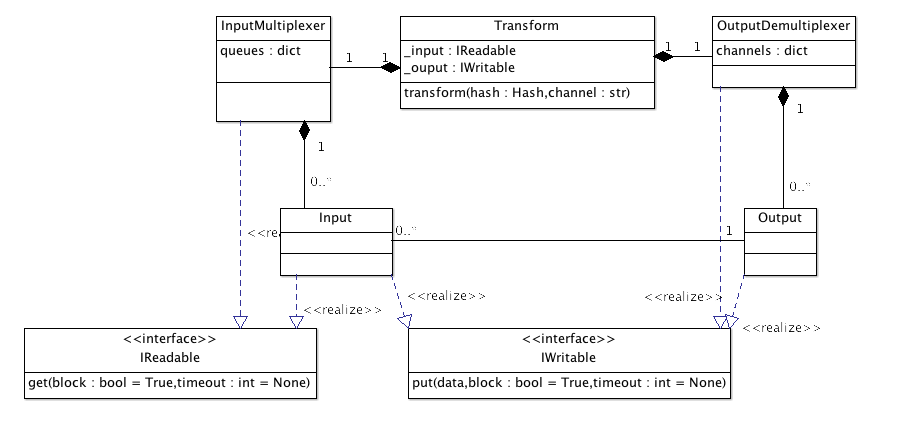
All you have to know as an ETL user, is that each transform may have 0..n input channels and 0..n output channels. Mostly because it was fun, we named the channel with representative *nix-file-descriptor-like names, but the similarity ends to the name.
The input multiplexer will group together whatever comes to one of the inputs channels and pass it to the transformation’s transform() method.
The transform method should be a generator, yielding output lines (with an optional output channel id):
def transform(hash, channel=STDIN):
yield hash.copy({'foo': 'bar'})
yield hash.copy({'foo': 'baz'})
Input and output¶
All transforms are expected to have the following attributes:
- _input, which should implement IReadable
- _output, which should implement IWritable
When you’re using rdc.etl.transform.Transform, the base class will create them for you as an InputMultiplexer and an OutputDemultiplexer, each one having a list of channels populated after reading the INPUT_CHANNELS and OUTPUT_CHANNELS transformation attributes. By default, transformations have one default STDIN input, one default STDOUT output and one alternate STDERR output. You can virtually have infinite input or outputs in your transformations (as though I have hard time imagining a use).
Example¶
Here is a simple transform that takes whatever comes to STDIN and put it on STDOUT and STDOUT2, and that puts everything that comes to STDIN2 and send it to STDERR.
from rdc.etl.transform import Transform
from rdc.etl.io import STDIN, STDIN2, STDOUT, STDOUT2, STDERR
class MyTransform(Transform):
INPUT_CHANNELS = (STDIN, STDIN2, )
OUTPUT_CHANNELS = (STDOUT, STDOUT2, STDERR, )
def transform(self, hash, channel=STDIN):
if channel == STDIN:
yield hash
yield hash, STDOUT2
elif channel == STDIN2:
yield hash, STDERR